

《 xAI 》宣布 Grok
- 2023年11月17日
- 讀畢需時 5 分鐘
我們為什麼要建造 Grok
在 xAI,我們希望創造人工智慧工具,幫助人類尋求理解和知識。
通過創建和改進 Grok,我們的目標是:
收集反饋並確保我們正在構建能夠最大限度地造福全人類的 AI 工具。我們認為,設計對各種背景和政治觀點的人都有用的人工智慧工具非常重要。我們還希望在遵守法律的前提下,通過我們的人工智慧工具為我們的使用者提供支援。我們與 Grok 的目標是在公開場合探索和展示這種方法。
賦能研究和創新:我們希望 Grok 成為任何人的強大研究助手,幫助他們快速訪問相關信息、處理數據並提出新想法。
我們的最終目標是讓我們的人工智慧工具協助追求理解。
Grok-1 之旅
為 Grok 提供動力的引擎是 Grok-1,這是我們在過去四個月中開發的前沿 LLM。在這段時間里,Grok-1 經歷了多次反覆運算。
在宣佈 xAI 之後,我們訓練了一個具有 330 億個參數的原型 LLM (Grok-0)。這個早期模型在標準 LM 基準測試上接近 LLaMA 2 (70B) 功能,但只使用了一半的訓練資源。在過去的兩個月里,我們在推理和編碼能力方面取得了重大改進,最終推出了 Grok-1,這是一種功能更強大的最先進的語言模型,在 HumanEval 編碼任務中實現了 63.2%,在 MMLU 上實現了 73%。
為了了解我們對 Grok-1 所做的能力改進,我們使用一些旨在衡量數學和推理能力的標準機器學習基準進行了一系列評估。
GSM8k:中學數學單詞問題,(Cobbe 等人,2021 年),使用思維鏈提示。
MMLU:多學科多項選擇題(Hendrycks 等人,2021 年),提供了 5 個鏡頭的上下文示例。
HumanEval:P ython 代碼完成任務,(Chen 等人,2021年),pass@1評估為零樣本。
數學:用 LaTeX 編寫的初中和高中數學問題(Hendrycks 等人,2021 年),提示固定的 4 次提示。
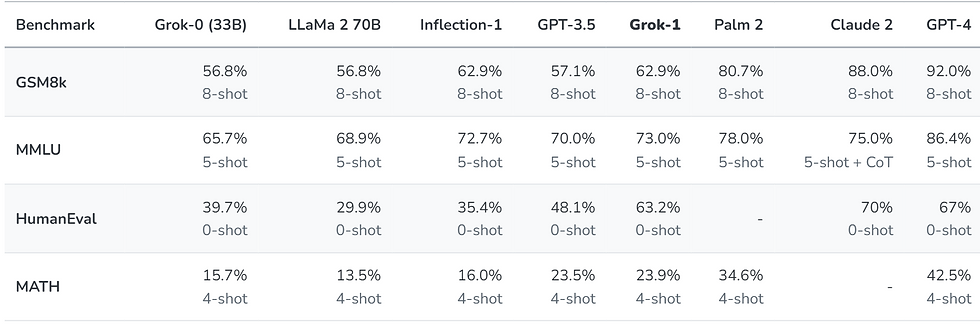
在這些基準測試中,Grok-1 表現出強勁的結果,超過了其計算類中的所有其他模型,包括 ChatGPT-3.5 和 Inflection-1。只有像 GPT-4 這樣使用大量訓練數據和計算資源進行訓練的模型才能超越它。這展示了我們在 xAI 以極高的效率訓練 LLM 方面取得的快速進展。
由於這些基準可以在網路上找到,我們不能排除我們的模型是無意中訓練的,因此我們在 2023 年匈牙利全國高中數學期末考試上對我們的模型(以及 Claude-2 和 GPT-4)進行了手工評分,該期末考試於 5 月底發布,在我們收集了數據集後。Grok 以 C (59%) 通過了考試,而 Claude-2 獲得了相同的成績 (55%),GPT-4 以 68% 的成績獲得了 B。所有模型均在溫度為0.1和相同提示下進行評估。必須指出的是,我們沒有為這次評估做出任何調整。這個實驗是對我們的模型從未明確調整過的數據集的「現實生活」 測試。

我們在模型卡中提供了 Grok-1 重要技術細節的摘要。
xAI 的工程設計
在深度學習研究的前沿,必須像構建數據集和學習演算法一樣謹慎地構建可靠的基礎設施。為了創建 Grok,我們構建了一個基於 Kubernetes、Rust 和 JAX 的自定義訓練和推理堆疊。
法學碩士培訓就像一列貨運列車在前方轟鳴;如果一節車廂脫軌,整個列車就會被拖離軌道,很難再次直立。GPU 失敗的方式有很多種:製造缺陷、連接鬆動、配置不正確、記憶體晶元退化、偶爾的隨機位翻轉等等。在訓練時,我們連續數月在數以萬計的 GPU 之間同步計算,並且由於規模的原因,所有這些故障模式都變得頻繁。為了克服這些挑戰,我們採用了一套定製的分散式系統,確保立即識別並自動處理每種類型的故障。在 xAI,我們將最大限度地提高每瓦有用計算能力作為我們工作的重點。在過去的幾個月里,我們的基礎設施使我們能夠最大限度地減少停機時間,即使在硬體不可靠的情況下也能保持較高的模型浮點運算利用率 (MFU)。
Rust 已被證明是構建可擴展、可靠和可維護的基礎設施的理想選擇。它提供了高性能、豐富的生態系統,並防止了人們通常會在分散式系統中發現的大多數錯誤。鑒於我們的團隊規模較小,基礎設施的可靠性至關重要,否則,維護工作會扼殺創新。Rust 讓我們相信,任何代碼修改或重構都可能產生工作程式,這些程式將在最少的監督下運行數月。
我們現在正在為模型能力的下一次飛躍做準備,這將需要可靠地協調數以萬計的加速器上的訓練運行,運行互聯網規模的數據管道,並在 Grok 中構建新的功能和工具。如果這聽起來讓您感到興奮,請在此處申請加入團隊。
xAI 的研究
我們允許 Grok 訪問搜尋工具和實時資訊,但與所有在下一個標記預測上訓練的 LLM 一樣,我們的模型仍然會產生錯誤或矛盾的資訊。我們認為,實現可靠的推理是解決當前系統局限性的最重要研究方向。在這裡,我們想重點介紹一些我們在 xAI 最感興趣的有前途的研究方向:
通過工具輔助實現可擴展的監督。人類的反饋是必不可少的。但是,提供一致且準確的反饋可能具有挑戰性,尤其是在處理冗長的代碼或複雜的推理步驟時。人工智慧可以通過查找來自不同來源的參考資料、使用外部工具驗證中間步驟以及在必要時尋求人工反饋來協助進行可擴展的監督。我們的目標是在模型的説明下最有效地利用人工智慧導師的時間。
與形式驗證集成,確保安全性、可靠性和接地。為了創建能夠對現實世界進行深入推理的人工智慧系統,我們計劃在不那麼模棱兩可和更可驗證的情況下發展推理技能。這使我們能夠在沒有人類反饋或與現實世界交互的情況下評估我們的系統。這種方法的一個主要直接目標是為代碼的正確性提供正式的保證,特別是在人工智慧安全的形式可驗證方面。
長期上下文理解和檢索。在特定環境中有效發現有用知識的訓練模型是產生真正智慧系統的核心。我們正在研究可以在需要時發現和檢索資訊的方法。
對抗性魯棒性。對抗性示例表明,優化人員可以很容易地利用人工智慧系統中的漏洞,無論是在訓練期間還是在服務期間,都會導致它們犯嚴重的錯誤。這些漏洞是深度學習模型長期存在的弱點。我們對提高 LLM、獎勵模型和監控系統的魯棒性特別感興趣。
多模式功能。目前,格羅克沒有其他感官,例如視覺和聽覺。為了更好地説明使用者,我們將為 Grok 配備這些不同的感官,以實現更廣泛的應用,包括即時交互和輔助。
我們相信,人工智慧具有巨大的潛力,可以為社會貢獻重要的科學和經濟價值,因此我們將努力制定可靠的保障措施,防止災難性的惡意使用。我們相信盡最大努力確保人工智慧仍然是一股向善的力量。
如果您和我們一樣樂觀,並希望為我們的使命做出貢獻,請在此處申請加入團隊。
搶先體驗 Grok
我們在美國為有限數量的使用者提供試用我們的 Grok 原型並提供有價值的反饋,這將有助於我們在更廣泛地發佈之前改進其功能。您可以在此處加入 Grok 候補名單。此版本只是 xAI 的第一步。展望未來,我們有一個令人興奮的路線圖,並將在未來幾個月內推出新的功能和特性。
以上內容來自 [ xAI ] x.ai































