

《 Meta 》通過人工智慧保護世界語言多樣性
- 2023年6月1日
- 讀畢需時 2 分鐘
支援數千種語言
世界上許多語言都有消失的危險,當前語音辨識和生成技術的局限性只會加速這一趨勢。我們希望讓人們更容易以他們的首選語言訪問資訊和使用設備,今天我們宣佈了一系列人工智慧(AI)模型,可以幫助他們做到這一點。
大規模多語言語音 (MMS) 模型將文本轉語音和語音轉文本技術從大約 100 種語言擴展到 1,100 多種語言(是以前的 10 倍多),還可以識別 4,000 多種語言,是以前的 40 倍。
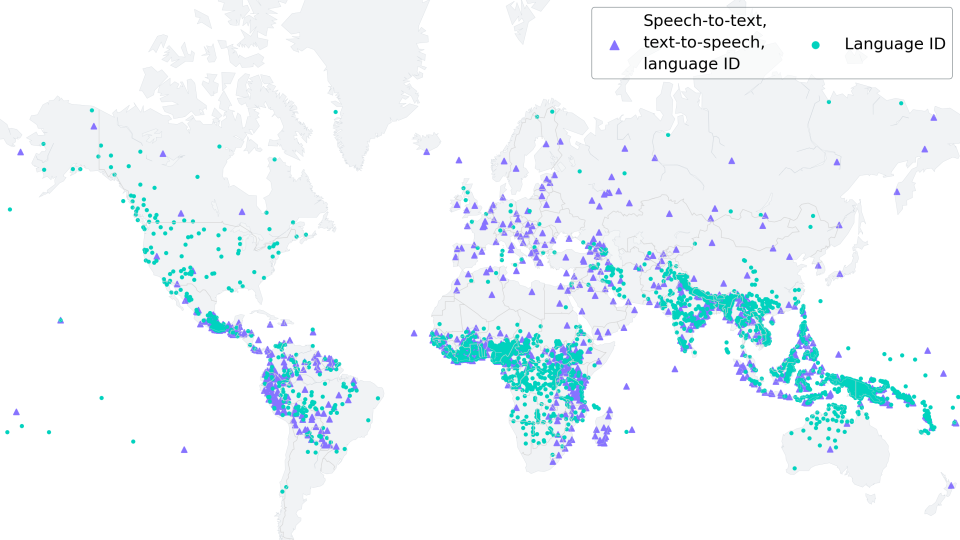
語音技術也有許多用例 - 從虛擬實境和擴增實境技術到消息傳遞服務 - 可以用一個人的首選語言使用,並且可以理解每個人的聲音。
我們正在開源我們的模型和代碼,以便研究社區中的其他人可以在我們的工作基礎上進行構建,並幫助保護世界語言並使世界更緊密地聯繫在一起。
我們的方法
收集數千種語言的音訊數據是我們的第一個挑戰,因為現有的最大的語音數據集最多涵蓋 100 種語言。為了克服這個問題,我們轉向宗教文本,例如聖經,這些文本已被翻譯成許多不同的語言,並且其翻譯已被廣泛研究用於基於文本的語言翻譯研究。
這些譯本有人們用不同語言閱讀這些文本的公開錄音。作為 MMS 專案的一部分,我們創建了一個超過 1,100 種語言的新約閱讀數據集,每種語言平均提供 32 小時的數據。
考慮到其他各種基督教宗教讀物的未標記錄音,我們將可用的語言數量增加到 4 多種。雖然這些數據來自特定領域,並且通常由男性說話者閱讀,但我們的分析表明,我們的模型在男性和女性聲音方面表現同樣出色。雖然錄音的內容是宗教的,但我們的分析表明,這不會使模型產生更多的宗教語言。
展望未來
未來,我們希望擴大 MMS 的覆蓋範圍以支援更多語言,並解決處理方言的挑戰,這對於現有的語音技術來說通常是困難的。
以上內容來自 [ Meta Newsroom ] about.fb.com/news/2023/05/ai-massively-multilingual-speech-technology































